DNS TAPIR Information Management
Summary
The challenge in analyzing DNS data is mainly that of gaining access to it. From a privacy perspective, singular queries are largely unproblematic, but an individual’s query stream taken over time will give a detailed description of their Internet activities. As a consequence, DNS resolver operators are reluctant to share their data with anyone.
This is unfortunate, since DNS is an excellent source of information on the state of the Internet - both for legitimate and other activities. Criminals are of course ardent users of DNS, but most corporations also use DNS to deliver their services, of which some also misuse DNS to track their visitors. With DNS being an obscure protocol at the network borderlands, what happens there is largely opaque and invisible, even though the Internet stops the instant DNS breaks. Our goal is to lend visibility to everything that occurs in the DNS ecosystem, and to do so without compromising the privacy of the querying party.
Privacy risks for the DNS system
Basic principles
The guiding principle for collecting DNS data is that the querying party remains anonymous. If correlation across data sources is taken into account, the DNS data has a number of parameters that, taken separately or in concert, can reconnect the data to the requestor. Sequences of queries can also be used to fingerprint the requestor, even if no other data is available.
Identifiers
Identifiers are keys that connect the querying party to their query stream.
Protocol related identifiers
All DNS queries regardless of transport method will contain the querying party’s IP-address (either IPv4 or IPv6). When using encrypted transport methods, if the session keys used for encryption are reused for some period of time, then it uniquely identifies where a particular stream of queries came from during that time. Queries can contain other identifiers, such as EDNS Client Subnet (ECS, rfc7871) or DNS Cookies (rfc7873) which may also connect a stream of queries to a specific requestor.
- IP addresses, actual or pseudonymised, are never sent to TAPIR Core
- To approximate the number of querying clients, the method HyperLogLog is used (https://en.wikipedia.org/wiki/HyperLogLog) using the querying party’s actual IP address
- The IP address of a querying party is pseudonymised using CryptoPAn (https://en.wikipedia.org/wiki/Crypto-PAn) when stored to disk locally in TAPIR Edge
- Identifiers found in EDNS0, cryptographic keys or hashes, and similar identifying labels are never sent to TAPIR Core
Example:
When using DNS over HTTPS the session key is frequently reused to increase performance. If the responding resolver index incoming queries based on this key, this will link all queries as coming from one client for the lifespan of that session key. This is true even when using privacy enhancing methods such as ODoH. Analyzing these grouped queries using fingerprinting or similar strategies can allow you to track the queries of specific clients without knowledge of their source IP address.
Indirect identifiers
Frequently the question itself identifies the querying party. A classical example (no longer valid) was when the default computer name for several operating systems was “Firstname Lastname’s computer”, which leaked onto the Internet through the system’s DNS queries. Modern versions include sending unique hashes or seemingly random characters that, either by themselves or by data encoded in them, contain identifying information. Even a random string, if reused, can be used to connect different queries to the same querying party and connect their movements between websites (or systems).
- Known indirect identifiers seen in queries are never sent to TAPIR Core
- Possible identifiers found in analysis that appear to leak personal data or identify querying parties are added to patterns that are removed
Example:
A unique identifier, say 3d829a910cb3e.trck.example.com., is sent as an event to TAPIR Core in its explicit form while unknown, without the client IP address or neighboring queries. Once the query format is identified and classified as a tracking domain, the query is aggregated as a subdomain query to trck.example.com.
Time
Exact time allows for easy correlation to other data sources related to the same communication, such as the web server logs the DNS names relate to. This correlation could reconnect an identifying IP address to those queries, and thereby possibly allow other, unrelated queries from the same querying party to be identified.
- Histogram data is grouped into intervals of one minute, joining all querying parties within that minute into one report
- Notifications have timestamps, but these relate to when the notification was generated and not to request or response times
- Data stored locally at the edge does have precision timestamps. These are used by the local analysis process, but only derived data where the timestamps are removed are submitted for analysis
Example:
When the querying party asks for
2024-05-01T12.22.33.232 client 198.51.100.33 asked for <www.example.com>
This is pseudonymised when stored in local logs as follows,
2024-05-01T12.22.33.232 client 192.2.0.66 asked for <www.example.com>
The querying party will use the information received in the response to access the web server for
2024-05-01T12.22.33.485 <www.example.com> connect from 198.51.100.33
Someone with access to both the DNS and web server logs can derive which real IP address corresponds to a pseudonym IP address, and can thereby reidentify queries with that pseudonym even when they are unrelated to the original query. To make such correlation difficult, labeling data with exact time is avoided.
Precision
Parameters related to queries, such as sequence numbers, flags, etc can leak information about the source and simplify correlation. Even if there is no exact timestamp, timing between queries can provide information about unrelated queries from the querying party.
The DNS TAPIR methodology of separating data into different categories that are handled by different machanisms breaks the connection between queries and makes it difficult to measure timing or identify identifying flag settings.
- Time series with higher time accuracy than one minute exist only locally on TAPIR Edge
- Sequence numbers, port numbers, and similar data is not sent to TAPIR Core
Exqmple:
This is difficult to exemplify as most clients randomise port and sequence numbers with the intention of preventing attacks such as DNS poisoning, making them irrelevant for analysis. In the unlikely event that a client has predictable behaviour, it cannot be abused. For time series analysis, see below.
Privacy sensitive correlation
The query pattern itself can create an identifying fingerprint. The operating system one uses, the software installed, the services used, generate queries when checking for updates or connecting to servers that the services use. The pattern created by these queries can be used to link other queries to the same querying party. From a privacy perspective, query sequences create a mosaic of the requestor’s online movement that provides for effective profiling (see Mosaic theory). To mitigate this privacy threat, analytical methods that take this into account are required, such as k-anonymity or Differential Privacy.
- The data processing methods used in DNS TAPIR aim to break the data into categories, making it impossible to recover the sequence of queries from a querying party.
- Sequences that are analysed are only available in TAPIR Edge, and with all known domains excluded
Example:
Users usually have a large number of automated services installed on their computer, such as email, chat, video conferencing software, social media, weather apps, stock quotes to name a few.
All of these frequently connect to servers on the Internet and thus also query the DNS. The domain names and the pattern in which they are queried create a fingerprint that can identify the user, for example
2024-05-01T12.22.33.932 client 198.51.100.33 query mymail.example.com
2024-05-01T12.22.34.011 client 198.51.100.33 query icq.example.com
2024-05-01T12.22.34.152 client 198.51.100.33 query weather.example.com
2024-05-01T12.22.34.292 client 198.51.100.33 query stocks.example.com
2024-05-01T12.22.34.606 client 198.51.100.33 query osupdate.example.com
2024-05-01T12.22.35.122 client 198.51.100.33 query teamster.example.com
and later:
2024-05-01T12.23.33.788 client 198.51.100.33 query mymail.example.com
2024-05-01T12.22.33.992 client 198.51.100.33 query icq.example.com
2024-05-01T12.22.34.111 client 198.51.100.33 query stocks.example.com
2024-05-01T12.22.34.888 client 198.51.100.33 query teamster.example.com
Roughly the same queries, similar order and synchronised in time, repeating continuously as long as one is connected makes it possible to follow a querying party without other identifiers.
DNS TAPIR analysis system
To meet the information management requirements needed to handle data from DNS, DNS TAPIR has designed a system with clear boundaries of responsibility for stored data and data flows.
The critical division is between TAPIR Edge, which is the part of the system managed by a DNS resolver operator, and TAPIR Core, which is run by - frequently an independent - core operator.
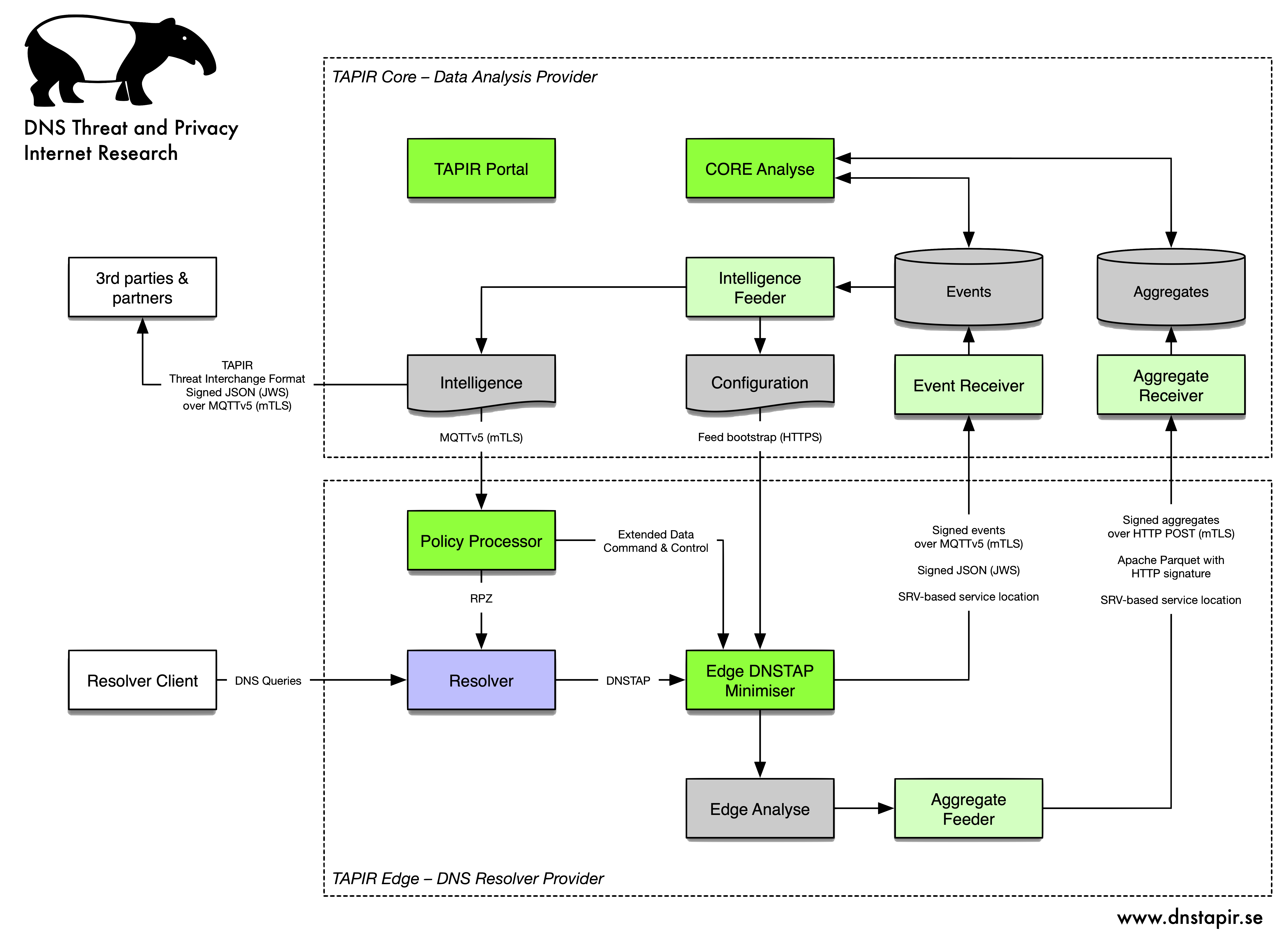
Image 1: System overview for DNS TAPIR
Data collection
DNS data is collected by a number of actors, whether commercial, non-profit or governmental, and at different levels of the system. Commercial actors are mostly found in cybersecurity, as criminals often exploit DNS.
The fact that only a few take their data at the resolver level has several reasons, including the fact that data volumes are highest there, that they need access to systems deployed regionally - their own or others’ - and infrastructure to ship collected data home.
Another reason is that DNS data that can be linked to an individual is deeply privacy sensitive and allows mapping of interests, habits, organisational affiliations, political and religious views, etc., which makes responsible ISPs treat DNS logs as toxic and not share them with anyone.
The challenge DNS TAPIR is trying to solve is not to collect and analyse DNS data. This is a relatively simple problem given current technology. The challenge is to be able to collect data and analyse it in such a way that Swedish ISPs allow us to do so on data from their customers. Privacy frames the problem and the challenge is to create equally relevant data within that frame.
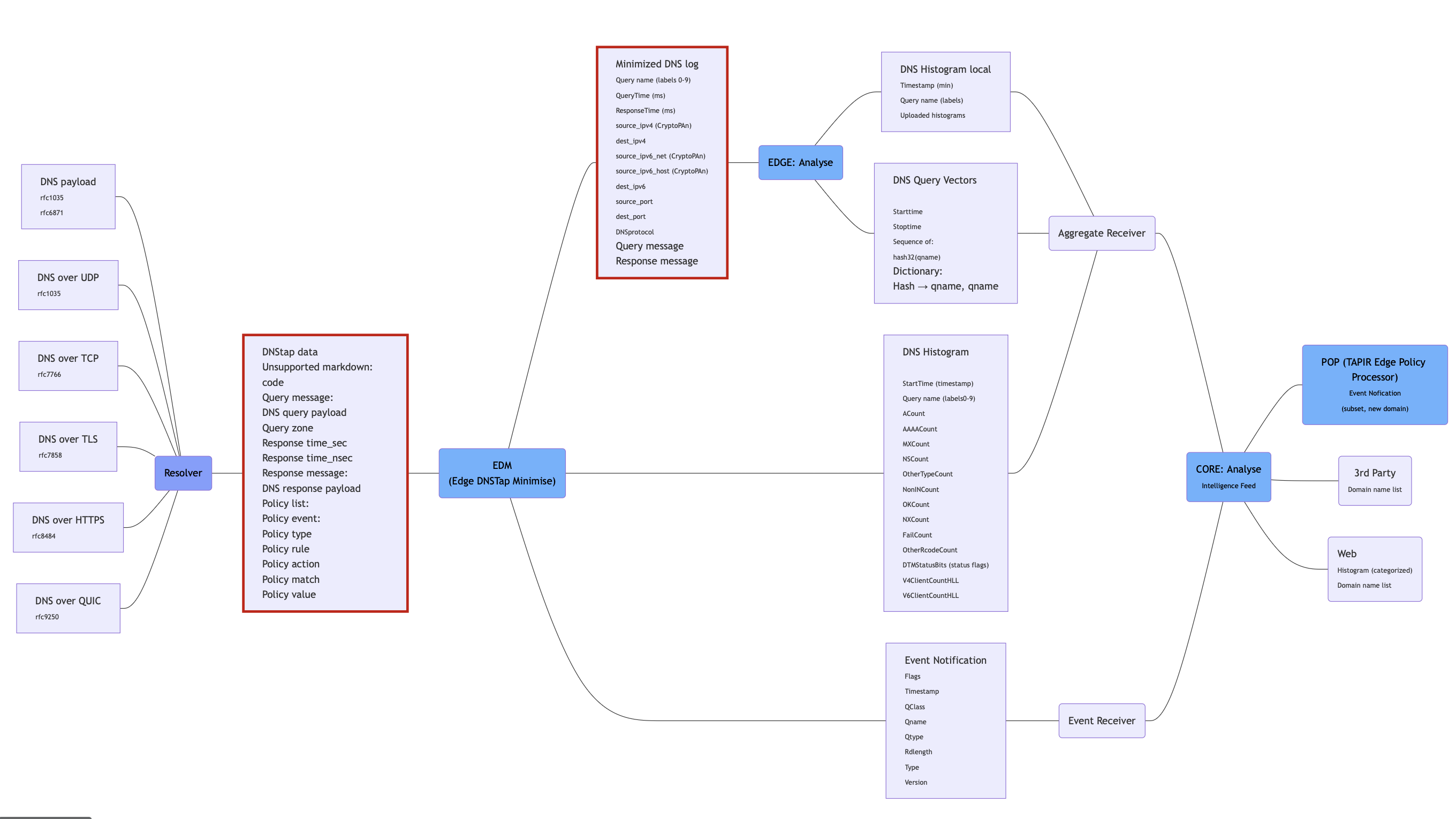 Image 2: TAPIR Data Flow
Image 2: TAPIR Data Flow
TAPIR Edge
TAPIR Edge is the part of the system that delivers DNS services, collects data from it, does local filtering, minimisation and analysis of this data and sends the scrubbed data for centralised analysis in TAPIR Core. TAPIR Edge also receives configuration data from TAPIR Core, including filtering lists, lookup tables, etc.
- All components of TAPIR Edge are open source and all data structures created by the system are publicly documented
- Data sent from TAPIR Edge is encrypted in transit and signed, but fully available for the system owner to review
- Data sent to TAPIR Edge is encrypted in transit and signed, also fully accessible for the system owner
DNS Resolver
The DNS resolver can in theory be any one that meets the requirement that it can deliver query data via DNSTAP. The one currently used for the development of the system is Unbound.
The data collected from the resolver is all the queries and answers it handles from the requesters using the system. Data is delivered continuously via DNSTAP with a size-limited buffer.
- Data from the resolver is highly privacy sensitive and exists only in the interface between the resolver and the collector Edge DNSTAP Minimise (EDM, see below)
- Data is not stored in raw form on persistent storage media
- Data in the DNSTAP protocol is a superset of the data sent, as different amounts of it are implemented in different resolvers
The schema for all data that may exist in DNSTAP can be found in https://github.com/dnstap/dnstap.pb/blob/master/dnstap.proto
Edge DNSTAP Minimise (EDM)
The EDM listens to everything the resolver generates, but there is no guarantee that all traffic will be processed (i.e. best effort). This is a design choice, as the data collection must not adversely affect the functioning of the resolver and the analysis must be able to work with incomplete information. This follows partly from how DNSTAP works, but also from the fact that the system must be robust in its function.
As the name DNSTAP Minimise indicates, the main task is to reduce the rather substantial amounts of data delivered by the resolver. In short, this is to collate information about all domain names that are commonly used (of limited interest such as
The data sent from the EDM to TAPIR Core is:
- Histogram data in minute intervals based on selected domains
- Notification of a specific domain name
Data stored for local analysis in Edge Analysis are:
- The full DNS transaction (query and response) with identifiers removed or pseudonymised for the queries not compiled in the histogram above
(Schema definitions can be found in appendix 1 for histograms, notifications in appendix 2 and DNS logs in appendix 4 )
TAPIR Edge Policy Processor (POP)
The Policy Processor component does not have access to privacy-sensitive information, but is mentioned because it can be used to manipulate the responses that the resolver sends to the querying party. This is intentional, as this feature also allows, for example, filtering out malicious domain names, blocking denial of service attacks, etc. when used correctly. It can also be misused to redirect the querying party to different websites than those intended or censor information by blocking traffic to domains hosting undesired information.
- TAPIR Edge Policy Processor uses many different sources for the data that modifies the resolver response.
- Both the choice of sources and the behaviour of the resolver are controlled by the system owner.
- The system owner also chooses what is done with the information coming from DNS TAPIR.
- Information from DNS TAPIR is always available in plain text for review.
Edge Analyse
Questions that cannot be directly identified and aggregated by the EDM are generally more interesting but at the same time more individual-specific and unique to the querying party. Therefore, Edge contains a local analysis engine called Edge Analyse, that processes this data to further minimise information that can be linked to the querying party before sending information to TAPIR Core.
One example is to anonymise identifying information contained in the query itself. The output of this process is identical to the histogram data created by the EDM, but with a set of rules for what is included and how. One example of such a rule is that long unique strings associated with specific domains or that exhibit specific patterns are removed, and a generic label indicating the type of pattern is instead added to the output.
Another is that queries with unknown patterns are delivered decoupled from the querier, where other related data is minimised and shifted in time. The time period covered by these histograms is also longer than that of EDM to increase the number of queries and clients.
The local analysis also allows sequences of data linked to a specific querying party to be compiled anonymously. Query sequences can be used to, for example, track changes in the behaviour of botnet C2 domains, or find previously unknown C2 domains related to the same botnet.
Vectorisation of sequences, compilation of these and their global dictionaries is primarily done locally and later merged in TAPIR Core to find global similarities in individual query patterns.
- Local analysis is done using heuristic rules and standardised analysis methods, all open source and publicly documented.
- From the local analysis, in addition to histograms and notifications, a data structure is sent containing vectorised query sequences with associated dictionary.
- Labels are generated using a frequent collision hash function, which makes fingerprinting difficult.
- Sequences are never longer than one hour, and exclude known domains
- The system owner has full control over what is transmitted
The schema for histograms and notifications is the same as for EDM. The scheme for vectors is described in appendix 3.
TAPIR Core
Data collected and minimised in TAPIR Edge is sent to TAPIR Core, where it is stored and analysed. Much of this analysis is done on DNS data decoupled from other data sources, aiming to identify different attributes that may be of interest.
Correlation to other data can be done when open data sources exist. However, the main purpose of DNS TAPIR is to make DNS data transparent and available to interested parties by addressing the challenge of it being highly privacy sensitive.
DNS messages themselves are very sparse in terms of information content but when aggregated across broad groups of clients and DNS providers, indications of criminal activity, misuse of DNS for tracking or information gathering, manipulation of the DNS system itself, and similar activities can be found.
In almost all cases, the querying party is either the victim of the activities themselves or the victim of activities that abuse the requester’s equipment.
DNS data tends to grow quickly into very large data sets, so the minimisation process that started in Edge also continues in Core. The goal is to retain as much of the information value as possible and continuously evaluate this value in relation to the amount of retained data, and then aggressively cull the data - partly as a further protection of privacy but mainly to avoid getting caught up in collecting data for the sake of collecting.
- TAPIR Core shall never be considered as a Data Processor as defined by the GDPR. This means that data in TAPIR Core shall not be traceable to a querying party, and that all responsibility for identifying information remains with the system owner (Data Owner under the GDPR).
- Data in TAPIR Core is mainly linked to the domain name. For these domain names, statistics and attributes found in data collected from TAPIR Edge are stored, but also results from the analysis process such as generated query results, data from third-party sources, and notes from more in-depth analysis.
Core Event Receiver
Notifications are delivered from TAPIR Edge to TAPIR Core through a message bus. These messages are received by the Event Receiver and aggregated in various forms into Core Analyse for analysis. These messages are signed with a key unique to each TAPIR Edge instance and the data stream is encrypted in transit, but the information itself can always be reviewed by the system owner.
Core Aggregate Receiver
Aggregates and vectors sent from TAPIR Edge are received by the Aggregate Receiver, which organises and stores the data in TAPIR Core. The information is signed with a key unique to each TAPIR Edge instance and the data stream is encrypted in transit, but the information itself can always be reviewed by the system owner and is stored in plaintext on the analysis platform
Core Analyse
At the center of TAPIR Core is the data analysis system. This includes computational clusters for distributed processing, processing tools for automated processes, and analytical tools for data analysts to develop new methods and models for processing DNS data.
The input data is mainly the datasets coming from TAPIR Edge, but other data sources related to DNS data are also used. A prerequisite for the use of a given dataset is that this data is free of privacy-sensitive information and free to use without restrictions on correlated data.
Core Observation Feed
The benefit of DNS TAPIR is the insights and attributes that can be found in the DNS data. These are provided through the reports created by analysis. Some of these reports are automated and generated continuously. They can be used internally, shared with third parties or published publicly. Publication may be delayed against certain channels, such as domains linked to criminal activities to provide Information Security actors some time to react to threats before they become public.
To summarise the often extensive data that comes from analysis and control what and to whom information is sent, data is filtered into the Core Observation Feed. To whom and with what delay is to be seen as purely administrative, while what is sent is decided on based on threshold values for what is interesting.
Notifications can also be filtered and shared. One such example is a truly new domain, i.e. one that we have not seen being queried on any resolver in recent months and which also generates a valid response, something that can be used for so-called ‘greylisting’ and a function that can be implemented by the Edge Policy Processor.
Histogram data are popularity lists based on a given attribute. These in turn can be broken down into categories based on selection rules. Distinctive features are provided as tags by analysis and lists can be generated based on one or more distinct features.
Below are examples of reports from Observation Feed.
| Data sent from TAPIR Core | Delay | Recipient |
|---|---|---|
| Notification, new existing domain | none | POP, partners |
| List of domains of interest | none | partners |
| Histogram, top 1000 domain names categorised | none | public |
| List of domains of interest | 24 timmar | public |
Table 1: TAPIR Core dataset. Datasets, time delays and recipients that currently exist or are planned. This will change over time.
More detailed documentation on which reports exist and which attributes the selection is based on will be found linked to the API for Observation Feed, as results from analysis are constantly evolving
Data Retention
There are two distinct data domains in DNS TAPIR with very different qualities. The TAPIR Edge system and its data is under the control of the resolver operator, whereas TAPIR Core is (usually) run by an independent entity. Data that is collected, processed and stored in TAPIR Edge will be tainted by various degrees of PII data, whereas data in TAPIR Core should be disconnected from the querying party to a level where anynymity is preserved even when correlating with other data sources.
TAPIR Edge
All data on TAPIR Edge should be considered privacy sensitive. The protocols and interfaces for transmitting data from TAPIR Edge to TAPIR Core are control points for validating that privacy guarantees are met. Retention times are ultimately under the control of the system owner.
| Data retention for TAPIR Edge | Time |
|---|---|
| Histograms and notifications from Minimise | 24 hours |
| Raw minimised DNS-logs on local storage | 24 hours |
| Vectors, notifications and histograms from Edge Analyse | 24 hours |
| Data stored in Edge Analyse feature store | 30 days |
Table 2: TAPIR Edge data retention. The table is limited to current and proposed data sets. Retention times should be viewed as recommendations.
TAPIR Core
Data retained in TAPIR Core must be purged of Personally Identifiable Information (PII). The usefulness of high granularity data diminishes over time, so stored data is over time aggregated with increasing periodicity.
Secondary data derived from the collected data is deleted based on a number of factors, age being one of them. The data can become irrelevant for other reasons as well, such as change of registration or ownership, or unregistered randomly generated domains with little remaining traffic.
| Data retention for TAPIR Core | Time |
|---|---|
| Histograms from TAPIR Edge | 7 days |
| Vector data from TAPIR Edge | 30 days |
| Notifications from TAPIR Edge | 3 months |
| Aggregated data, 5 minute interval | 3 months |
| Aggregated data, 1 hour interval | 13 months |
| Aggregated data, daily interval | not culled |
| Aggregated vector data with dictionary | not culled |
| Notifications without source information | not culled |
Table 3: TAPIR Core data retention. The table is limited to current and proposed data sets and is likely to change.
Dictionary
| Word | Meaning |
|---|---|
| DNS | Domain Name System, a distributed database that provides information related to domain names |
| Querying party | Individual or machine that queries the DNS system |
| Requestor | Querying party |
| ODoH | Oblivious DNS over HTTPS, a privacy-enhancement for DoH, DNS over HTTPS, aiming to disassociate a query from the IP address of the requestor |
| Recursive | See recursive |
| Resolver | System that provides the service of resolving names for a querying party |
| PII | Personally Identifiable Information, information identifying or closely related to a specific querying party |
References
- Website: https://www.dnstapir.se
- Github repo: https://github.com/dnstapir
- DNSTAP repo: https://github.com/dnstap
- DNS-related RFC: https://rfc-annotations.research.icann.org/
- Singanamalla, Sudheesh, et al. “Oblivious DNS over HTTPS (ODoH): A Practical Privacy Enhancement to DNS.” Proceedings on Privacy Enhancing Technologies (2021).
- Arana, Oscar, et al. “Never Query Alone: A distributed strategy to protect Internet users from DNS fingerprinting attacks.” Computer Networks 199 (2021): 108445.
- Chang, Deliang, et al. “Hide and Seek: Revisiting DNS-based User Tracking.” 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P). IEEE, 2022.
- Mosaic Theory http://fastercapital.com/content/Data-Analytics--Data-Analytics--The-Mosaic-Theory-of-Interpreting-Information.html
- k-anonymity https://www.immuta.com/blog/k-anonymity-everything-you-need-to-know-2021-guide/
- Differential privacy https://www.cis.upenn.edu/~aaroth/privacybook.html