DNS TAPIR Informationshantering
Sammanfattning
Utmaningen med att analysera DNS-data är i första hand att överhuvudtaget få tillgång till det. Ur integritetsperspektiv är inte individuella frågor särskilt oroväckande, men sammantaget är de frågor en individ eller enhet (hädanefter frågeställare) ställer över tid en detaljerad beskrivning över deras aktiviteter på nätet. Detta gör att operatörer av DNS-servrar ytterst ogärna delar detta data med någon.
Samtidigt är DNS en källa till information om hur det står till med Internet, både för legitima och andra aktiviteter. Kriminella använder DNS flitigt, seriösa bolag använder DNS för att leverera olika tjänster, mindre seriösa bolag använder DNS för att spåra sina besökare, och allt detta är idag osynligt. När DNS stannar, stannar internet. Vårt mål är att synliggöra allt som händer inom DNS, utan att utsätta frågeställare för övergrepp på deras personliga integritet.
Riskfaktorer för personliga data i DNS
Grundprinciper
Den styrande principen för datainsamlingen är att frågeställaren som genererat de DNS-frågor som är till grund för allt insamlat data inte skall kunna identifieras. För att uppnå detta på en högre nivå där även korrelation mellan datakällor tas i beaktande, finns en rad parametrar som var för sig eller tillsammans kan återskapa kopplingen till frågeställaren. Även sekvenser av frågor kan, om de är tillräckligt långa, utan andra data ge information om frågeställaren.
Identifierare
Identifierare är nycklar som kopplar en given frågeställare till de frågor som denne ställer.
Protokoll-relaterade identifierare
Samtliga DNS-frågor oavsett frågemetod innehåller frågeställarens IP-adress (IPv4 eller IPv6). Vid användning av krypterade frågemetoder är även sessionsnycklar för krypteringen, om de återanvänds för flera frågor, att betrakta som identifierande. En fråga kan bifogas ytterligare identifierare, som exempelvis EDNS Client Subnet (ECS, rfc7871) eller DNS Cookies (rfc7873), som också kopplar sekvenser av frågor till en specifik frågeställare.
- IP-adresser, riktiga eller pseudonymiserade, skickas aldrig till TAPIR Core
- För att approximera kardinalitet av klientantal globalt används metoden HyperLogLog (https://en.wikipedia.org/wiki/HyperLogLog) på frågeställarens riktiga IP-adress
- Frågeställarens IP-adress pseudonymiseras med CryptoPAn (https://en.wikipedia.org/wiki/Crypto-PAn) när den lagras på persistent media lokalt i TAPIR Edge
- Identifierare i EDNS0, kryptografiska artefakter och liknande direkta identifierare skickas aldrig till TAPIR Core
Exempel:
För DNS over HTTPS återanvänds ofta sessionsnyckeln för att öka prestanda. Om den svarande resolvern kopplar frågorna till denna nyckel, kommer detta att länka samman frågeställarens frågor under tiden som nyckeln används, och detta är sant även för ODoH när den inre nyckeln återanvänds. Med dessa grupperade frågor kan frågeställaren följas över tid med exempelvis metoder för fingerprinting, helt utan kännedom om frågeställarens IP-adress.
Indirekta identifierare
Det är inte ovanligt att innehållet i DNS-frågan indirekt identifierar frågeställaren. Ett klassiskt exempel (som inte längre förekommer) var att standardnamnet på datorer var ”förnamn efternamn’s dator”, något som läckte ut i DNS-frågor från maskinen. Moderna varianter på detta är att skicka frågor med unika teckensträngar som förefaller slumpmässiga men kan innehålla identifierande information. Om de upprepas eller ett mönster kan härledas till en specifik frågeställare, kan sekvenser av frågor kopplas till frågeställaren.
- Indirekta identifierare i enskilda frågor som följer kända mönster skickas aldrig till TAPIR Core
- Okända identifierare som hittas vid analys och misstänks kunna identifiera en specifik frågeställare adderas till de mönster som filtreras bort
Exempel:
En identifierare som är unik, som exempelvis 3d829a910cb3e.trck.example.com., skickas till Core i denna form när den är okänd, men utan koppling till IP-adress eller relaterade frågor. När Core identifierat och klassificerat denna som identifierande kommer den istället sammanställas under trck.example.com.
Tid
Med kännedom om den exakta tidpunkt en fråga ställts, kan data från andra källor lätt korreleras med de frågor de har gemensamt, exempelvis loggar från de webbservrar som frågeställaren slagit upp namnen för. Information från dessa loggar kan då återföra identifierare som IP-adresser till motsvarande fråga, och därmed också andra frågor som kan härledas till samma frågeställare.
- Histogramdata sammanställs i minutintervall, där samtliga frågeställare under den minuten klumpas samman i rapporten
- Notifikationer har tidsstämplar men dessa är baserade på när notifieringen skickas, inte när frågan anlände eller besvarades
- Lokalt har data tidsstämplar med stor noggrannhet som används av den lokala analysmotorn. Detta data skickas aldrig obearbetat
Exempel:
När en frågeställare frågar efter
2024-05-01T12.22.33.232 client 198.51.100.33 asked for <www.example.com>
och detta sparas i DNS-loggarna pseudonymiserade, tex
2024-05-01T12.22.33.232 client 192.2.0.66 asked for <www.example.com>
Frågeställarens dator använder sedan denna IP-adress för att ansluta webbläsaren till den server som tillhandahåller
2024-05-01T12.22.33.485 <www.example.com> connect from 198.51.100.33
Någon med tillgång till både webbserverns loggar och loggarna för DNS kan hitta vilken riktig adress som motsvarar en pseudonym och därigenom veta vilka andra frågor som gjorts av samma frågeställare. För att försvåra denna typ av korrelation undviker vi exakta tidsangivelser.
Precision
Parametrar kopplade till frågor, exempelvis sekvensnummer, flaggor, med mera kan bidra till att data kan korreleras. Även om exakt tidsstämpel saknas, kan tiden mellan frågor ge information om frågeställaren och bidra till att andra frågor kan kopplas till samma frågeställare.
Den metodik som DNS TAPIR använder för att bryta upp tidsserier i olika kategorier förhindrar att man kan dra slutsatser både av frågesekvensens innehåll och avståndet mellan frågor.
- Tidsserier med större noggrannhet på tidsskalan än minut finns bara lokalt i TAPIR Edge
- Sekvensnummer, portnummer och liknande skickas inte till TAPIR Core
Exempel:
Det är svårt att exemplifiera då de flesta klienter slumpar ut port och sekvensnummer med avsikt att försvåra attacker, vilket gör dem irrelevanta för analys och därför oftast kan avfärdas för de flesta klienter. Om en klient mot förmodan har predicerbart beteende eller ställer stora mängder frågor som ger underlag för analys, skall man inte kunna missbruka det. Specifikt för tidsserieanalys, se nedan.
Integritetskänslig sammanställning
Frågemönstret i sig kan skapa ett identifierande fingeravtryck. Det operativsystem man använder, de programvaror som är installerade, de tjänster som används, genererar frågor när de letar efter uppdateringar eller ansluter till servrar som tjänsterna använder. Mönstret som dessa frågor skapar kan användas för att koppla andra frågor till samma frågeställare. Från ett integritetsperspektiv skapar frågesekvenser en mosaik av frågeställarens rörelser på nätet som möjliggör kartläggning (se Mosaic theory) och kräver analysmetoder som tar detta i beaktande, exempelvis k-anonymitet eller Differential Privacy.
- De metoder för bearbetning av data som används i DNS TAPIR syftar till att bryta isär data till kategorier, vilket gör det omöjligt att återställa sekvensen av frågor från en frågeställare.
- Sekvenser som analyseras finns enbart i TAPIR Edge och då med samtliga kända domäner exkluderade
Exempel:
Användare har som regel ett stort antal automatiska tjänster installerade på sin dator, exempelvis mail, chatt, videokonferensprogram, sociala medier, väderappar, börsnoteringar för att nämna några.
Samtliga dessa ansluter frekvent till servrar på Internet och frågar därmed också DNS. De domännamn och det mönster i vilket de efterfrågas skapar ett fingeravtryck som kan identifiera användaren, tex:
2024-05-01T12.22.33.932 client 198.51.100.33 query mymail.example.com
2024-05-01T12.22.34.011 client 198.51.100.33 query icq.example.com
2024-05-01T12.22.34.152 client 198.51.100.33 query weather.example.com
2024-05-01T12.22.34.292 client 198.51.100.33 query stocks.example.com
2024-05-01T12.22.34.606 client 198.51.100.33 query osupdate.example.com
2024-05-01T12.22.35.122 client 198.51.100.33 query teamster.example.com
Och senare:
2024-05-01T12.23.33.788 client 198.51.100.33 query mymail.example.com
2024-05-01T12.22.33.992 client 198.51.100.33 query icq.example.com
2024-05-01T12.22.34.111 client 198.51.100.33 query stocks.example.com
2024-05-01T12.22.34.888 client 198.51.100.33 query teamster.example.com
Ungefär samma frågor, liknande ordning och tidssynkront, som upprepar sig kontinuerligt så länge man än ansluten gör det möjligt att följa en frågeställare utan andra identifierare.
DNS TAPIR analyssystem
För att möta de krav på informationshantering som krävs för att hantera data från DNS, har DNS TAPIR konstruerat ett system där det finns tydliga gränser för ansvar för lagrade data och dataflöden.
Den mest centrala uppdelningen är mellan TAPIR Edge, som är den del av systemet som hanteras av DNS-operatören, och TAPIR Core som drivs av en - oftast oberoende - core-operatör.
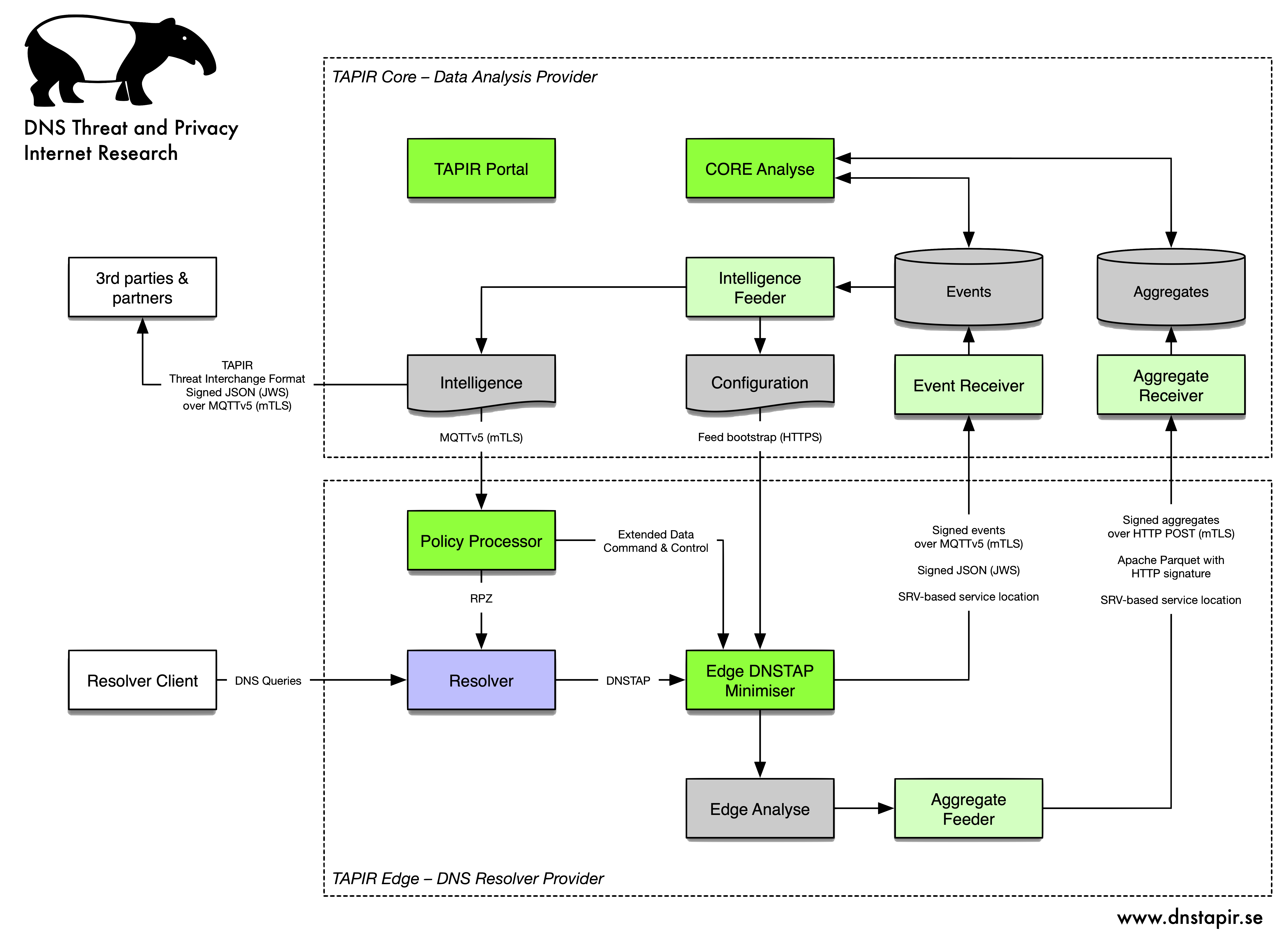
Bild 1: Systemöversikt DNS TAPIR
Datainsamling
Insamling av DNS-data görs av ett flertal aktörer, i kommersiell, ideell eller statlig regi, och på olika nivåer i systemet. Kommersiella aktörer finner man mestadels inom cybersäkerhet, då kriminella ofta utnyttjar DNS.
Att endast ett fåtal tar sitt data i resolverledet har flera orsaker, bland annat att datavolymerna är som störst där, att man behöver tillgång till system utplacerade regionalt - egna eller andras - och infrastruktur för att skeppa hem insamlat data.
Ett annat skäl är att DNS-data som går att koppla till en individ är djupt integritetskänsligt och möjliggör kartläggning av intressen, vanor, organisationstillhörighet, politiska och religiösa åsikter, med mera, vilket gör att ansvarstagande internetleverantörer behandlar DNS-loggar som toxiskt och inte delar dem med någon.
Utmaningen DNS TAPIR försöker lösa är inte att samla in och analysera DNS-data. Detta är ett relativt enkelt problem givet dagens teknologi. Utmaningen ligger i att kunna samla in data och analysera det på ett sådant sätt att svenska internetleverantörer tillåter oss att göra det på data från deras kunder. Den personliga integriteten sätter ramen och problemställningen är att skapa lika relevanta data inom den.
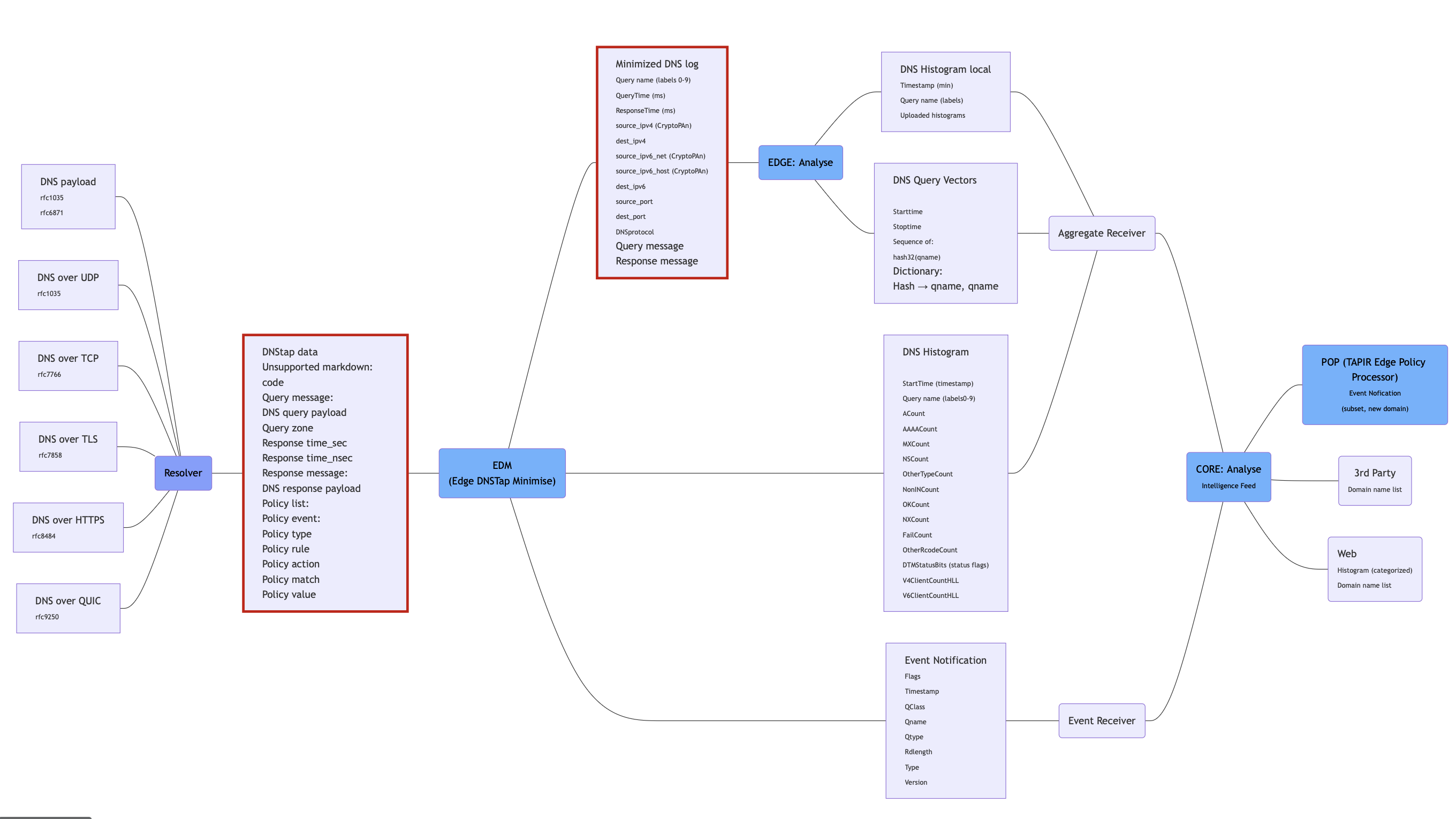 Bild 2: TAPIR Dataflöde
Bild 2: TAPIR Dataflöde
TAPIR Edge
TAPIR Edge är benämningen på systemet som levererar DNS-tjänsten, samlar in data från denna, gör lokal filtrering, minimering och analys av detta data, och skickar tvättat data till centraliserad analys i TAPIR Core. Från de centrala funktionerna kommer konfigurationsdata för TAPIR Edge och resolver, såsom filter listor, uppslagstabeller och liknade.
- Samtliga komponenter i TAPIR Edge är öppen källkod och alla datastrukturer som skapas av systemet är offentligt dokumenterade
- Data som skickas från TAPIR Edge är krypterade vid transport och är signerade, men fullt tillgängliga för systemägaren att granska
- Data som skickas till TAPIR Edge är krypterade vid transport och signerade, också fullt tillgängliga för systemägaren
DNS Resolver
Resolvern kan i princip vara en godtycklig sådan med det enda kravet att den kan leverera frågedata via DNSTAP. Den som för närvarande används för utveckling av systemet är Unbound.
Det data som samlas in från resolvern är samtliga frågor och svar som denna hanterar från de frågeställare som använder systemet. Data levereras kontinuerligt via DNSTAP med en begränsad buffert.
- Data från resolvern är ytterst integritetskänsligt, och existerar enbart i gränssnittet mellan resolvern och insamlaren Edge DNSTAP minimise (EDM, se nedan)
- Data lagras inte i obehandlad form på persistent lagringsmedia
- Data i DNSTAP-protokollet är ett superset av det data som skickas, då olika mycket av detta implementeras i olika resolvrar
Schema för alla data som kan finnas i DNSTAP återfinns i https://github.com/dnstap/dnstap.pb/blob/master/dnstap.proto
Edge DNSTAP Minimise (EDM)
Insamlaren EDM lyssnar på allt som resolvern genererar, men det finns ingen garanti för att all trafik hinner bearbetas (dvs ”best effort”). Detta är ett designval, då datainsamlingen inte får menligt påverka resolverns funktion och analysen måste kunna fungera med ofullständig information. Det följer dels av hur DNSTAP fungerar, men också utifrån att systemet skall vara robust i sin funktion.
Såsom namnet DNSTAP Minimise anger är den huvudsakliga uppgiften att minska ner de ganska väsentliga datamängder som levereras av resolvern. I korta drag är detta att sammanställa information om alla domännamn som är vanligt förekommande (av begränsat intresse som tex
Data som skickas från EDM till TAPIR Core är:
- Histogramdata i minutintervall baserat på selekterade domäner
- Notifiering om ett specifikt domännamn
Data som lagras för lokal analys i Edge Analyse är:
- Den fullständiga DNS transaktionen (fråga och svar) med identifierare borttagna eller pseudonymiserade för de frågor som inte sammanställts i histogram ovan
(Schema för histogram återfinns i bilaga 1, notifieringar i bilaga 2 och DNS-loggar i bilaga 4 )
TAPIR Edge Policy Processor (POP)
Administrationskomponenten POP har inte tillgång till integritetskänslig information, men omnämns då den kan användas för att manipulera de svar som resolvern skickar till frågeställaren. Detta är avsiktligt, då denna funktion också gör det möjligt att, exempelvis filtrera bort skadliga domännamn, blockera överbelastningsattacker, med mera när den används korrekt. Den kan också missbrukas för att dirigera om frågeställaren till andra webbsidor än de denne avsett eller blockera trafik till domäner man vill censurera.
- TAPIR Edge Policy Processor använder många olika källor för det data som modifierar resolverns svar.
- Både val av källor och hur resolvern skall agera kontrolleras av systemägaren.
- Systemägaren väljer också vad som görs med informationen som kommer från DNS TAPIR.
- Information från DNS TAPIR är alltid tillgänglig i klartext för granskning.
Edge Analyse
Frågor som inte direkt kan identifieras och aggregeras av EDM är mer intressanta men också mer individspecifika och unika för frågeställaren. Den lokala analysmotorn Edge Analyse processar därför detta data för att ytterligare minimera information som kan kopplas till frågeställaren innan informationen skickas till TAPIR Core.
Ett exempel är att anonymisera identifierande information som finns i själva frågan. Utdata från denna process är identisk med det histogramdata som EDM skapar, men med en rad regler för vad som inkluderas och hur. Ett exempel på en sådan regel är att långa unika strängar kopplade till specifika domäner eller som uppvisar specifika mönster tas bort, och i histogrammet anges en etikett som anger typen av mönster.
Ett annat är att frågor med okända mönster levereras frikopplade från frågeställaren, andra relaterade data minimeras och förskjutet i tid. Den tidsperiod som detta histogram omfattar är också längre än den för EDM för att öka antalet frågor och frågeställare.
Den lokala analysen gör det också möjligt att sammanställa sekvenser av data kopplat till en specifik frågeställare anonymt. Frågesekvenser kan användas för att exempelvis följa förändringar i beteende för botnet C2 domäner, eller hitta tidigare okända C2-domäner relaterade till samma botnet.
Vektorisering av sekvenser, sammanställning av dessa och deras globala ordlistor görs i första hand lokalt och slås sedan ihop centralt för att hitta globala likheter i frågemönster.
- Lokal analys görs med heuristiska regler och standardiserade analysmetoder, samtliga öppen källkod och offentligt dokumenterade
- Från den lokala analysen skickas, förutom histogram och notifieringar, en datastruktur innehållande vektoriserade frågesekvenser med tillhörande ordlista
- Etiketter genereras med en hash-funktion med frekventa kollisioner, som försvårar uppkomsten av fingeravtryck
- Sekvenser är aldrig längre än en timme, och exkluderar kända domäner
- Systemägaren har full kontroll över vad som tillåts
Schema för histogram och notifieringar är samma som för EDM. Schema för vektorer beskrivs i bilaga 3.
TAPIR Core
Data som samlas in och minimeras i TAPIR Edge skickas till TAPIR Core, där det lagras och analyseras. En stor del av denna analys görs på DNS-data frikopplat från andra datakällor, vilket syftar till att identifiera olika attribut som kan vara av intresse.
Korrelation till andra data kan göras när öppna datakällor finns. Huvudsyftet är dock att tillgängliggöra insyn i DNS-data för intresserade parter, något som är svårt då informationen är integritetskänslig.
DNS-meddelanden i sig själva är väldigt knapphändiga vad gäller informationsinnehåll, men sammantaget över breda grupper av frågeställare och DNS-leverantörer, framkommer mönster av kriminell aktiviteter, missbruk av DNS för informationsinsamling, manipulation av DNS-systemet i sig, och liknande.
I nästan samtliga fall är frågeställaren antingen offer för aktiviteterna i sig eller offer för aktiviteter som missbrukar frågeställarens utrustning.
DNS-data växer fort till att bli stora datamängder, så minimeringen som påbörjades i Edge fortsätter i Core. Målsättningen att bibehålla så stora delar av informationsvärdet som möjligt, att kontinuerligt utvärdera detta värde i relation till mängden kvarhållet data och aggressivt gallra data, dels som ett ytterligare skydd av personlig integritet men i huvudsak för att inte fastna i att samla för samlandets skull.
- TAPIR Core skall aldrig betraktas som Data Processor enligt definitionen i GDPR. Detta innebär att data i TAPIR Core inte skall kunna härledas till en frågeställare, och att allt ansvar för identifierande information ligger kvar hos systemägaren (Data Owner enligt GDPR).
- Data i TAPIR Core är i huvudsak kopplade till domännamnet. För dessa domännamn sparas statistik och attribut som hittats i insamlade data från TAPIR Edge, men också resultat från analysprocessen såsom genererade frågeresultat, data från tredjepartskällor, och noteringar från mer ingående analys.
Core Event Receiver
Notifieringar levereras från TAPIR Edge via en meddelandebuss. Dessa meddelanden tas emot av Event Receiver och aggregeras i olika former in till Core Analyse för analys. Dessa meddelanden är signerade med en för varje TAPIR Edge-instans unik nyckel och dataströmmen är krypterad under transport, men informationen i sig kan alltid granskas av systemägaren.
Core Aggregate Receiver
Aggregat och vektorer som skickas från TAPIR Edge tas emot av Aggregate Receiver. Dessa organiseras och lagras för att kunna analyseras i Core Analyse. Informationen är signerad med en för varje TAPIR Edge-instans unik nyckel och dataströmmen är krypterad under transport, men informationen i sig kan alltid granskas av systemägaren och lagras i klartext på analysplattformen
Core Analyse
Hjärtat i TAPIR Core är systemet för dataanalys. Detta består bland annat av beräkningskluster för distribuerad bearbetning, processverktyg för automatiserade processer, och analysverktyg för dataanalytiker att utveckla nya metoder och modeller för att bearbeta DNS-data..
Indata är i huvudsak de dataset som kommer från TAPIR Edge, men andra datakällor som relaterar till DNS-data används. En förutsättning för att ett givet dataset används är att detta data är fritt från integritetskänslig information och fritt att använda utan restriktioner på korrelerade data.
Core Observation Feed
Nyttan med DNS TAPIR är de insikter eller attribut som går att hitta i DNS-datat. Detta är de rapporter som analysen skapar. Vissa av dessa är automatiska och genereras kontinuerligt. De kan användas internt, delas med tredje part eller publiceras offentligt. Publiceringen kan vara fördröjd mot vissa kanaler, exempelvis domäner kopplade till kriminell verksamhet för att aktörer inom datasäkerhet skall hinna reagera.
För att sammanställa det ofta omfattande data som kommer från analys, och styra vad och till vem information skickas, filtreras data i Observation Feed. Till vem och med vilken fördröjning är att ses som rent administrativ, medan vad som skickas kan ses som ett tröskelvärde för vad som är intressant.
Notifieringar kan filtreras och delas, exempelvis kan en sant ny domän, det vill säga en som vi inte sett frågas efter på någon resolver de senaste månaderna, och som dessutom genererar ett svar med data användas för sk “greylisting”, något som POP kan hantera.
Histogramdata är i praktiken popularitetslistor baserade på ett givet attribut. Dessa kan i sin tur delas ner i kategorier baserat på urvalsregler. Utmärkande egenskaper anges som etiketter från analysen och man kan generera listor av domäner som har ett eller flera utmärkande drag.
Nedan följer exempel på rapporter från Observation Feed.
| Dataset som skickas från TAPIR Core | Fördröjning | Mottagare |
|---|---|---|
| Notifiering, ny domän som existerar | ingen | POP, partners |
| Lista, domännamn av intresse | ingen | partners |
| Histogram, top 1000 domäner i kategorier | ingen | offentligt |
| Lista, domännamn av intresse | 24 timmar | offentligt |
Tabell 1: TAPIR Core dataset. Dataset, tidsfördröjningar och mottagare är sådana som just nu finns eller planeras, och kan komma att förandras över tid.
Mer utförlig dokumentation kring vilka rapporter som existerar och vilka attribut urvalet är baserat på, återfinns kopplat till API för Observation Feed då utdata från analys ständigt utvecklas
Lagring av data
Data i DNS TAPIR kan delas upp i två distinkta grupper med olika förutsättningar. TAPIR Edge står under resolver-operatörens kontroll, medan TAPIR Core är core-operatörens ansvar.
Data som skapas och lagras i TAPIR Edge har olika grader av personlig information kopplade till sig, medan data i TAPIR Core skall vara anonymiserat och aggregerat på ett sådant sätt att det inte kan kopplas till specifika individer.
TAPIR Edge
Data i TAPIR Edge bör betraktas som integritetskänslig. De gränssnitt där information lämnar TAPIR Edge är kontrollpunkter där det säkerställs att inga personliga data exponeras. Gränserna för hur länge detta data sparas kan ändras av systemägaren.
| Kvarhållning av data i TAPIR Edge | Tidsrymd |
|---|---|
| Histogram och notifieringar från Minimise | 24 timmar |
| Minimerade DNS-loggar i råformat | 24 timmar |
| Vektorer notifieringar och histogram från Edge Analyse | 24 timmar |
| Data i Edge Analyse egenskapsdatabas (Feature store) | 30 dagar |
Tabell 2: TAPIR Edge lagring av data. Dataset är de som just nu finns eller planeras. Tider bör ses som rekommendationer.
TAPIR Core
Data i TAPIR Core skall vara fritt från integritetskänslig information. Dock är värdet av högupplösta data starkt avtagande över tid, så de datastrukturer som används aggregerar data över växande tidsfönster.
De databaser som genereras med information om domännamn raderar inte data baserat på enbart ålder, men gallras från utdaterad eller ointressant information kontinuerligt.
| Kvarhållning av data i TAPIR Core | Tidsrymd |
|---|---|
| Histogramdata från TAPIR Edge | 7 dagar |
| Vektordata från TAPIR Edge | 30 dagar |
| Notifieringar från TAPIR Edge | 3 månader |
| Aggregerade data i 5-minutersintervall | 3 månader |
| Aggregerade data i 1-timmesintervall | 13 månader |
| Aggregerade data i 1-dagsintervall | gallras inte |
| Aggregerat vektordata med ordlista | gallras inte |
| Notifieringar utan nod-information | gallras inte |
Tabell 3: Data från TAPIR Core. Tabellen visar de dataset som just nu finns eller planeras, och kommer sannolikt att ändras över tid.
Ordlista
| Ord | Betydelse |
|---|---|
| DNS | Domain Name System, systemet som publicerar information om domännamn. |
| Frågeställare | Individ eller dator som ställer en fråga till DNS-systemet |
| ODoH | Oblivious DNS over HTTPS, ett privacy-tillägg till DoH, DNS over HTTPS som syftar till att frikoppla DoH från IP-adressen hos frågeställaren |
| Rekursiv | Se rekursiv |
| Resolver | Server som gör rekursiva DNS-uppslag åt klienter |
Referenser
- Webbsida: https://www.dnstapir.se
- Github repo: https://github.com/dnstapir
- DNSTAP repo: https://github.com/dnstap
- DNS-relaterade RFC: https://rfc-annotations.research.icann.org/
- Singanamalla, Sudheesh, et al. “Oblivious DNS over HTTPS (ODoH): A Practical Privacy Enhancement to DNS.” Proceedings on Privacy Enhancing Technologies (2021).
- Arana, Oscar, et al. “Never Query Alone: A distributed strategy to protect Internet users from DNS fingerprinting attacks.” Computer Networks 199 (2021): 108445.
- Chang, Deliang, et al. “Hide and Seek: Revisiting DNS-based User Tracking.” 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P). IEEE, 2022.
- Mosaic Theory http://fastercapital.com/content/Data-Analytics--Data-Analytics--The-Mosaic-Theory-of-Interpreting-Information.html
- k-anonymity https://www.immuta.com/blog/k-anonymity-everything-you-need-to-know-2021-guide/
- Differential privacy https://www.cis.upenn.edu/~aaroth/privacybook.html